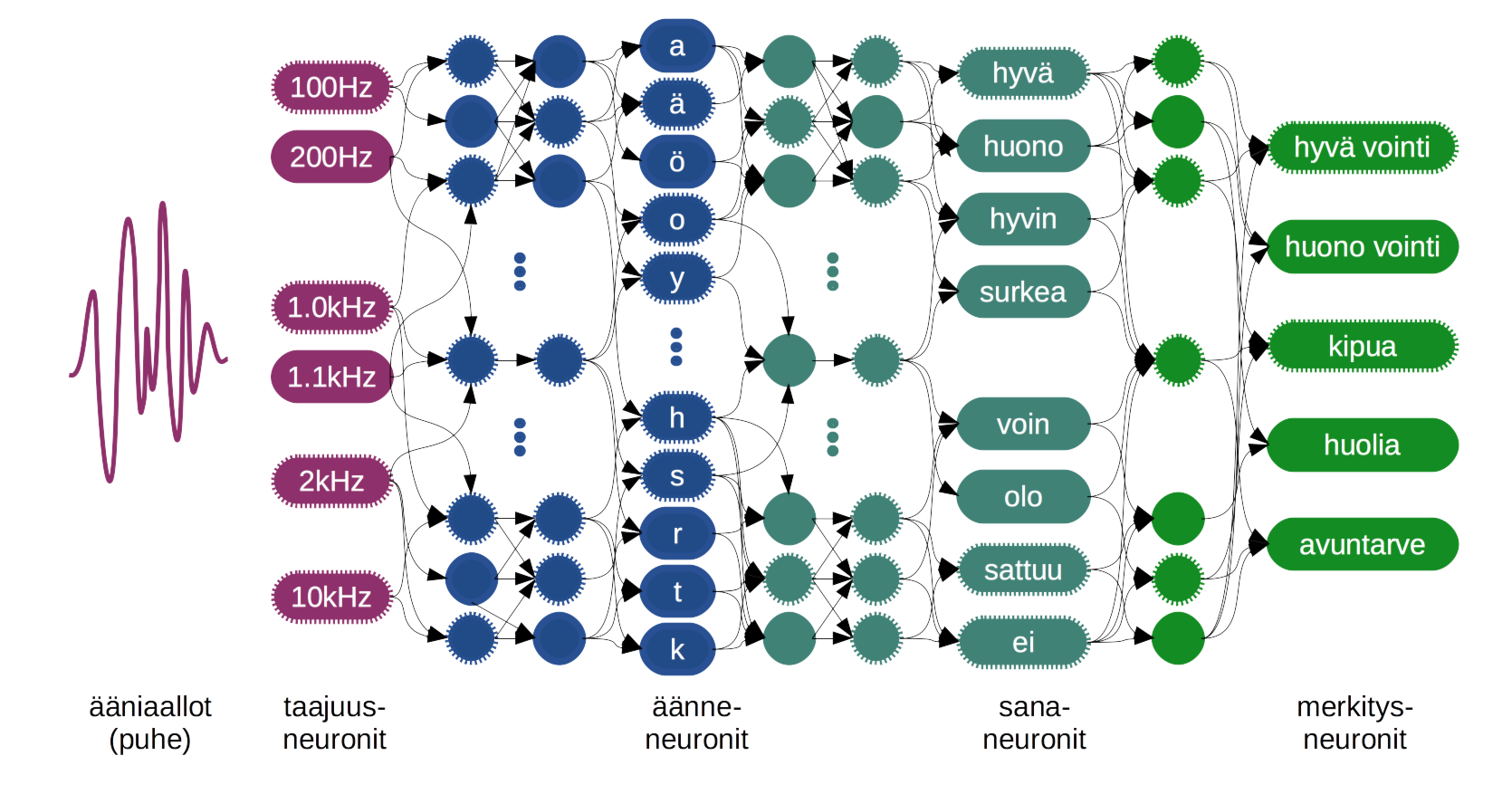
Me Onervalla kehitämme Onerva Bottia eli keskustelevaa tekoälyä vanhushoivaan. Tällä kertaa pääset itse kokeilemaan tekoälyn kanssa juttelua! Teemme suomea ymmärtävän tekoälyn alusta loppuun ja upotamme sen verkkosivuun. Valitettavasti et pääse juttelemaan tekoälyn kanssa sote-politiikasta, mutta se ymmärtää, onko vastaus kysymykseen “Mites tänään sujuu?” positiivinen vai negatiivinen. Tai no, kuten tulet huomaamaan… Ymmärtää, jos sille on opetettu tarpeeksi samantyyllisiä lauseita.
Etkö jaksa lukea blogitekstiä, vaan haluat heti kokeilemaan? Mene silloin tänne, ja kokeile seuraavia lauseita sekä muutamaa omaa.
“Ihan tosi hyvin!” “No, ei kyllä mene kovin hyvin.” “Terve terve, ei tässä kovin kivasti mene tai oikeastaan ihan surkeasti.” “Huomenta päivää. Kyllä tässä pärjäilen ihan kohtalaisesti, tai no, itseasiassa melko kehnosti.” “No moi! Voin kyllä aivan surkeasti... paitsi että oikeasti sujuu kyllä oikein mainiosti.”
Älä kuitenkaan ylläty, jos tekoäly tulkitsee jonkin lauseen väärin, vaan lue eteenpäin, niin ymmärrät miksi.
Itseasiassa on hämmästyttävää, miten hyvin tekoäly ymmärtää eri vastauksia ottaen huomioon käytetyn neuroverkon koon, koulutusaineiston laadun sekä sen, että tekoäly toimii selaimessa – siis ilman pilveä tai palvelinta!
Jos et ole vielä lukenut blogisarjan aiempia osia (osa 1, osa 2, osa 3, osa 4), kannattaa tutustua ennen kuin jatkat eteenpäin, koska tulemme viittaamaan niihin alla. Rakennamme siis tällä kertaa luonnollista kieltä ymmärtävän tekoälyn (osa 1) luomalla aluksi koulutusaineiston (osa 4), sitten muutamme lauseet sanavektoreiksi (osa 2) ja lopulta rakennamme neuroverkon, jolla on työmuisti (osa 3).
Koulutusaineisto
Blogin osassa 4 keskustelimme siitä, että teköälyn kouluttamisessa laadukkaan koulutusaineiston hankkiminen on usein työlästä. Tarvitaan valtavia määriä tekstiesimerkkejä, jotka ihminen on tulkinnut tekoälylle sopivaksi koulutusdataksi. Yksi tapa helpottaa tätä prosessia on automatisoida se osittain antamalla koneen korvata sanoja ja lausahduksia niiden synonyymeillä tai antonyymeillä. Tällä tavoin voidaan luoda uutta koulutusaineistoa alkuperäisestä datasta. Samalla voidaan tasapainottaa eri tyyppisten vastausten jakaumaa. Harvinaisia vastaustyyppejä luodaan paljon lisää, kun taas yleisiä vastaustyyppejä vain vähän tai jopa karsitaan.
Bang! Ensimmäinen python-koodin pätkä, jossa määritellään lausetyypit (sentence_types).
def generate_sentence(self):
sentence_types = [
"pos",
"neg",
"not_pos",
"not_neg",
"pos pos",
"pos neg",
...,
"not_pos pos",
...,
"not_neg not_pos"
]
Tyyppi “pos” vastaa positiivista lausetta, esimerkiksi “hyvin menee”. Tyyppi “not_pos” on negatiivinen lause, jossa positiivinen ilmaus on kääntynyt negatiiviseksi “ei”-sanan vaikutuksesta, esimerkiksi “ei hyvin mene”. Yhdistelmä “not_pos pos” tarkoittaa näiden kahden lausetyypin yhdistelmää, jossa jälkimmäinen lause jää voimaan, esimerkiksi “ei hyvin mene, tai no, ihan kohtalaisesti”. Tyyppi “neg” on taas negatiivinen lause, esimerkiksi “huonosti mene”. Loput voitkin näistä loogisesti päätellä.
Joka kerta kun luodaan uusi lause, valitaan yksi näistä tyypeistä satunnaisesti:
sentence_type = np.random.choice(sentence_types)
Oletetaan, että tällä kertaa valittiin “pos”-tyypin lause.
def generate_positive(self):
opt1 = [
"", "", "", "", "",
"ihan", "melko", "oikein", "aika", "tosi",
"ihan melko", "ihan kyllä", "kyllä tässä", "kyllä tässä ihan"
]
adj = [ "hyvin", "mainiosti", "loistavasti",
"oksti", "kohtalaisesti", "kivasti" ]
Positiivisen lauseen ydin on adjektiivi “adj”, joka on lista positiivisia synonyymejä, esimerkiksi “hyvin” ja “loistavasti”. Lisäksi on määritelty mahdollisia lisäsanoja “opt1”, jotka voivat esiintyä ennen adjektiivia. Jokaisella listan vaihtoehdolla on yhtä suuri mahdollisuus tulla valituksi, joten “ihan” tai “kyllä tässä ihan” esiintyvät 1/19 todennäköisyydellä ennen adjektiivia. Viisi tyhjää (“”) tarkoittavat, että on 5/19 todennäköisyys sille, että ylimääräistä sanaa ei lisätä adjektiivin eteen.
Tämä on nyt tietysti hyvin yksinkertaistettu versio synonyymien ja lisäsanojen luomisesta. Tässä on tavoiteltu luettavuutta tehokkuuden sijaan. Todellisuudessa kattavammat vaihtoehdot luodaan automaattisesti sääntöjen avulla, joissa sanoja yhdistellään ja korvataan eri todennäköisyyksin. Periaate on kuitenkin sama.
Lauseeseen tarvitaan myös (mahdollinen) verbi “verb” sekä lisäsanat “opt2” ja “opt3”, jonka jälkeen päästään luomaan positiivinen lause kahdesta vaihtoehtoisesta sanajärjestyksestä:
return np.random.choice([
opt1 + ' ' + adj + ' ' + opt2 + ' ' + verb + ' ' + opt3,
opt2 + ' ' + verb + ' ' + opt1 + ' ' + adj + ' ' + opt3
])
Tuloksena on esimerkiksi “ihan hyvin tässä menee”.
Vastaavasti kuin yllä kuvattu “pos” -tyypin lause, voidaan luoda myös muut lausetyypit “neg”, “not_pos” ja “not_neg”. Jos lauseen tyyppi on yhdistelmä “pos neg”, luodaan positiivinen ja negatiivinen lause, jotka yhdistetään esimerkiksi “tai no” lausahduksella yhdistelmälauseeksi “ihan hyvin menee tai no oikeastaan aika kehnosti”.
Nyt voimme luoda helposti laajan koulutusaineiston, esimerkiksi 10 000 lausetta, jonka käsin tuottamiseen olisi mennyt ikä ja terveys.
Läheskään kaikki luodut lauseet eivät ole hyvää suomenkieltä, esimerkiksi:
tosi loistavasti nyt kohtalaisesti nyt paitsi kovin surkeasti terve oksti kai tässä paitsi en pärjäile kyllä tässä huonosti no moi ei huonosti tänään terve en pärjäile kovinkaan surkeasti
Mutta lauseet ovat ymmärrettäviä, joka on tärkeintä tekoälyn koulutuksen kannalta. Tavoitehan on, että tekoäly osaa tulkita myös epätäydellisiä lauseita ja tilanteita, joissa puheesta tekstiksi -käännös ei ole onnistunut täydellisesti.
Sanoista vektoreja
Seuraavaksi muutamme lauseet neuroverkolle sopivaan muotoon. Aluksi luomme sanavektorit (ks. osa 2):
word_to_index_map = { '': 0 }
index_to_word_map = { 0: '' }
next_word_index = 1
for sentence in sentences:
words = sentence.split()
for word in words:
if not word in word_to_index_map:
word_to_index_map[word] = next_word_index
index_to_word_map[next_word_index] = word
next_word_index += 1
Eli käymme kaikkien lauseiden kaikki sanat läpi ja lisäämme ne tietokantaan “word_to_index_map”. Tietokanta sisältää sanan ja sitä vastaavan sanavektorin (one-hot word vector). Seuraavaksi muunnamme lauseet jonoiksi sanavektoreita:
def sentence_to_wordvecs(sentence):
words = sentence.split()
indexed_sentence = []
for word in words:
if word in word_to_index_map:
indexed_sentence.append(word_to_index_map[word])
else:
indexed_sentence.append(0)
return np.array(indexed_sentence)
Nyt lauseemme ovat valmiita syötettäväksi neuroverkolle.
Neuroverkon rakennus
Rakennamme verkon käyttäen pythonia ja Keras-koneoppimiskirjastoa. Aloitamme luomalla ensimmäiseksi kerrokseksi sanojen upotuskerroksen (word embedding layer).
model = Sequential() model.add(Embedding(max_index, 4, input_length=max_length))
Blogin osassa 2 käytimme esikoulutettua 300-ulotteista FastTextiä upotusten tekemiseen, mutta yksikertaisuuden ja suorituskyvyn vuoksi käytämme nyt upostusta, joka opitaan koulutuksen aikana. Periaate on kuitekin sama eli tämä kerros tiivistää yksinkertaiset sanavektorit ainoastaan 4-ulotteisiksi sanojen upotusvektoreiksi.
Seuraavaksi lisäämme kaksi kerrosta kaksisuuntaisia lyhyen työmuistin neuroneita (ks. osa 3), jotka oppivat koulutuksen aikana tulkitsemaan lauseiden merkityksiä:
model.add(Bidirectional(LSTM(6,return_sequences=True))) model.add(Dropout(0.3)) model.add(Bidirectional(LSTM(2))) model.add(Dropout(0.3))
Ensimmäinen kerros muuntaa jonon sanojen upotusvektoreita kahdeksi uudeksi jonoksi 6-ulotteisia vektoreita. Yksi jono eteenpäin kulkevalle tiedolle ja toinen taaksepäin. Seuraava kerros koostaa nämä jonot kahdeksi 2-ulotteiseksi vektoriksi. Dropout -kerrokset pudottavat satunnaisesti sanoja/vektoreita pois lauseista estäen ylioppimista.
Lopulta lisäämme kerroksen jossa on kaksi neuronia. Ensimmäinen neuroni aktivoituu, jos vastaus on negatiivinen ja toinen, jos vastaus on positiivinen.
model.add(Dense(2, activation='sigmoid'))
Neuroverkko on nyt valmis, joten seuraavaksi koulutamme sen. Sitä varten tarvitsemme neuroverkon optimointialgoritmin koodinimeltään “Adam”. Koska koulutamme neuroverkosta luokittelijaa, käskemme Adamin minimoimaa “kategorista ristientropia”.
optimizer = Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False) model.compile(optimizer, 'categorical_crossentropy', metrics=['accuracy'])
Ja sitten vaan koulutus käyntiin, syöttämällä neuroverkolle koulutusaineisto (x_train, y_train), muutama parametri ja testiaineisto (x_test, y_test):
model.fit(
x_train,
y_train,
batch_size=batch_size,
epochs=nepoch,
validation_data=[
x_test,
y_test
]
)
Kun koulutus on valmis, tallennamme sen tiedostoon tulevaa käyttöä varten.
model.save('bilstm.h5')
Ja siinäpä se. Muutama sata riviä koodia ja kupponen kahvia koulutuksen valmistumista odotellessa.
Ymmärtääkö se?
Koulutuksen jälkeen voidaan testata verkkoa.
value = model.predict(indexed_sentences, batch_size=1)[0]
Tuloksena “value” on vektori, jossa on kaksi elementtiä. Jos lause oli negatiivinen, vektori on [1; 0] tai ainakin lähellä sitä. Ja jos lause on positiivinen, vektori on [0; 1]. Esimerkiksi
“ihan kivasti menee” => [ 0.001; 0.994 ] “ei kovin kivasti mene” => [ 0.930; 0.003 ]
Mutta jotta pääsemme kokeilemaan tekoälyä selaimessa, muunnetaan se tensorflow.js yhteensopivaksi verkoksi:
tensorflowjs_converter --input_format keras bilstm.h5 www
Nyt voimme ladata tekoälyn verkkosivulle (javascriptillä) ja tulkita lauseiden merkityksiä suoraan selaimessa:
tf.loadLayersModel('model.json')
.then(model => {
const input = tf.tensor2d([indexed_sentence], [1, max_length])
const prediction = model.predict(input);
const value = prediction.dataSync();
});
Voit käydä täällä kokeilemassa, kuinka hyvin blogissa rakennettu tekoäly toimii.
Eihän se täydellinen ole. Ei lähelläkään. Vaikkapa “hyvin huonosti”, tulkitaan positiiviseksi! Miksi?
Ensinnäkin neuroverkko on hyvin pieni, alle tuhat muuttujaa, kun tyypillisissä tuotantotason verkoissa muuttujia on miljoonia. Voisimme helposti kasvattaa verkon kokoa ja antaa verkolle keskittymiskyvyn, mutta nämä toimet eivät yksinään paranna tekoälymme ymmärrystä yhtään. Miksi? Koska se osaa jo kaiken sille opetetun!
Ainoa tapa parantaa tekoälymme ymmärrystä on lisätä koulutusaineiston laajuutta. Suoraviivainen parannus olisi käyttää esikoulutettua sanojen upotusta, joka laajentaa koulutusaineistoa epäsuorasti. Parempia tuloksia saadaan kuitenkin suoraan laajentamalla lisäsanojen valikoimaa, lisäämällä synonyymejä ja antonyymeja, luomalla uusia lauserakenteita, lisäämällä neutraaleja lauseita, ottamalla huomioon kirjoitus-/litterointivirheet ja murteet… Mitähän vielä? Kerro meillekin.
Ja tietenkään tätä prosessia ei kannata alkaa käsin tekemään. Olemmekin kehittämässä oppivaa työkalua, jonka avulla ihminen voi tehokkaasti ohjata konetta luomaan laajoja koulutusaineistoja esimerkkien pohjalta.
Tämä blogisarja päättyy tähän tai ainakin jää hetkeksi tauolle. Ehdotuksia uusista aiheista otetaan toki vastaan. Jos toivot tarkempaa tietoa luonnollista kieltä ymmärtävien tekoälyjen kehittämisestä, niin ota toki yhteyttä!
P.S. Jos koodaaminen sujuu, haet koodit täältä ja testaa itse. Hyvä harjoitus on korjata “hyvin huonosti” lausahduksen tulkinta.