Me Onervalla kehitämme Onerva Bottia eli keskustelevaa tekoälyä vanhushoivaan. Ensimmäisessä osassa tätä blogisarjaa käsiteltiin asiaa yleisellä tasolla. Toisessa osassa kuvattiiin kuinka lauseet muutetaan neuroverkolle sopivaan muotoon käyttämällä sanojen upotusta (word embedding) ja mitä upotukset kertovat ”sanojen luonteesta”. Tässä osassa käydään läpi kuinka sanat muodostavat merkityksiä ja kuinka lauseen eri osat nivoutuvat yhteen neuroverkon työmuistin avulla.
Luonnollisen kielen ymmärtäminen vaatii, että tekoäly pystyy käsittelemään lauseiden eri osien välisiä yhteyksiä. Esimerkiksi jos vanhus vastaa kysymykseeen ”kuinka voitte tänään?”, seuraavasti
– Eipä tässä kurjuutta kummempaa, vähän päätä särkee…
(pitkä selitys naapurin kissasta)
– Vähän kyllä sydämestä ottaa… se tykyttää aikalailla…
– On tässä kyllä aika huono olo
Tekoälyn täytyy ymmärtää, että viimeinen lause kumoaa alun letkautuksen. Lisäksi sen pitää osata yhdistää ”se” sydämeen, mutta naapurin kissa pitäis jättää jotenkin huomiotta.
Tutkimalla viime aikaisia tieteellisiä artikkeleja päädyimme käyttämään kaksisuuntaisia pitkän työmuistin neuroverkkoja, joilla on keskittymiskyky. Huh, meniköhän suomennos ihan täydellisesti – no, mutta englanniksi siis ”bidirectional long short-term memory network” ja ”attention mechanism”. Avataanpa näitä hieman käsitteitä. Tässäkin tapauksessa lienee paras käyttää ihmisen ajatusprosessia esimerkkinä.
Neuroverkkoja olemme jo käsitelleet yleisesti blogin ensimmäisessä osassa ja on riittävää tietää, että niissä on keinotekoisia neuroneita, jotka reagoivat tietynlaisiin ärsykkeisiin eli signaaleihin tietyllä tapaa. Blogisarjan ensimmäisessä osassa käytimme esimerkkinä neuronia, joka aktivoituu, kun se havaitsee ääniaalloissa äännettä ”y” vastaavan taajuusyhdistelmän.
Tällä kertaa kuitenkin käsittelemme lauseita, jotka on muutettu sarjaksi sanojen upotusvektoreita, kuten blogisarjan toisessa osassa kuvattiin. Eli nyt ensimmäiset neuronit aktivoituvat sanan ja sen kontekstin mukaan.
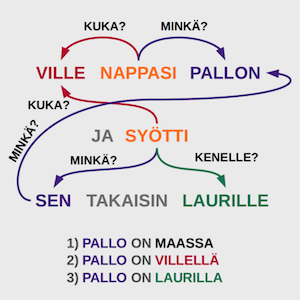
Aloitetaan perehtymään keskittymiskyvyllisiin, kaksisuuntaisiin pitkän työmuistin neuroverkkoihin tutustumalla niiden työmuistiin. Lue seuraava teksti ja vastaa ”kysymykseen kenelle pallo jäi?”.
Lauri otti pallon käteen ja heitti sen koria kohti, mutta se pomppasi korin renkaasta maahan. Ville nappasi pallon ja syötti sen takaisin Laurille. Ville käveli vesipullonsa luo, otti sen käteensä ja joi.
Mielessäsi tapahtuu ainakin kolme vaihetta: 1) pallo on Laurilla, 2) pallo on Villellä, 3) pallo on Laurilla. Neuroverkolla on tässä jo kova homma. Ilman työmuistia tehtävä on lähes mahdoton yleisessä tapauksessa.
Ensimmäinen ongelma on sana ”se”. Sana ”se” on viittaus aikaisempaan sanaan, joten aikaisemmat sanat pitää muistaa. Jos neuroverkko ei osaa yhdistää sanaa ”se” toiseen sanaan, se vastaa on todennäköisesti, että pallo jäi Villelle, koska ”Ville nappasi pallon”. Tai ehkä se vastaa kuitenkin Lauri, koska ”Lauri otti pallon käteen” ja ilman työmuistia lauseiden järjestys menee helposti sekaisin.
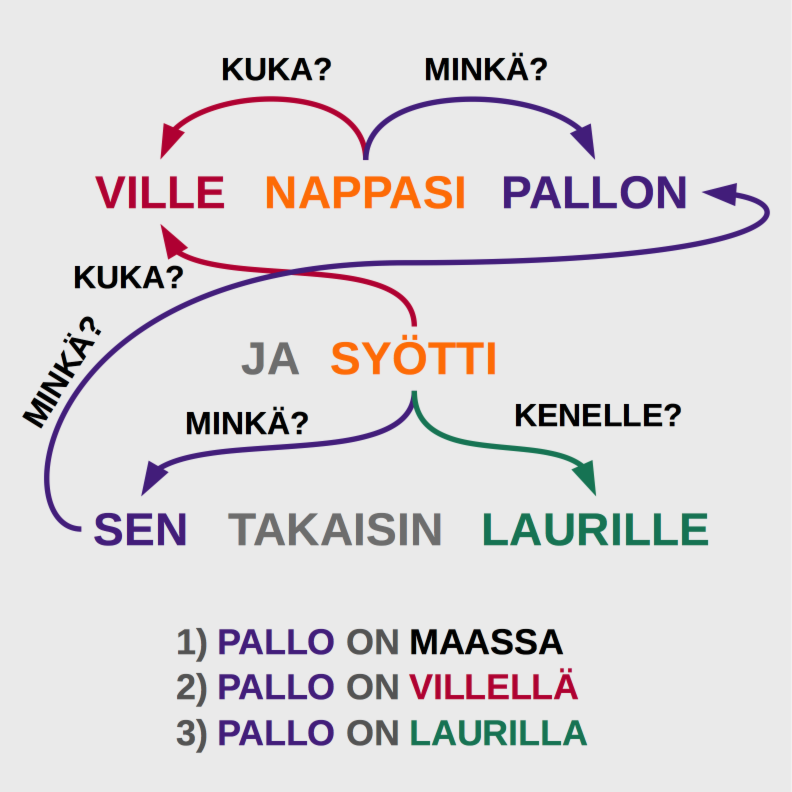
Toinen ongelma on edelleen ”se”, sillä ensimmäinen ”se” viittaa palloon, mutta viimeinen ”sen” vesipulloon. Tilastollisesti ”se” viittaa kuitenkin useimmiten sanaan ”pallo” ja ilman työmuistia neuroverkko mahdollisesti ehdottaisi viimeisen ”sen” viittaavan palloon ja vastaisi pallon jääneen Villelle. Neuroverkon täytyy siis pystyä muistamaan mihin sanaan ”se” liittyy, mutta myös unohtamaan, että ”se” liittyi aiemmin palloon korvaamalla pallo työmuistissaan vesipullolla.
Neuroverkon työmuistille oleelliset ominaisuudet ovat siis edeltävien asioiden muistaminen, mutta yhtälailla unohtaminen (tarvittaessa).
Neuroverkon pitkä työmuisti viittaa siihen, että muistin kestoa ei ole rajoitettu, vaan asiat tallentuvat ja unohtuvat lähimuistin neuroneihin niihiin tulevien ärsykkeiden perusteella. Ilman ärsykkeeseen perustuvaa muistamista ja unohtamista neuroneihin tallentuva tieto ”väljähtyisi”, jos tarinassa olisi paljon asiaan liittymätöntä tietoa. Esimerkiksi jos yllä olevaan tekstiin lisättäisiin paljon kuvausta pallon ulkonäöstä, pallon liikkeistä ja henkilöiden reaktioista, kysymykseen vastaaminen muuttuisi vaikeammaksi tekstin pituuden kasvaessa ilman ärsykkeisiin perustuvaa työmuistia.
Ärsykkeisiin perustuva työmuisti mahdollistaa pitkäkestoisen muistin.
Pitkän työmuistin neuroneilla onkin normaalin syöte-vaste -reaktion lisäksi muista- ja unohda-reaktiot. (Itseasiassa syöte jakautuu normaaliksi syötteeksi, muista-portin syötteeksi, unohda-portin syötteeksi ja vaste-portin syötteeksi. Lue pitkän lähimuistin neuroneista lisää täältä.)
Entäpä kaksisuuntaisuus? Mihin sitä tarvitaan? Ei välttämättä mihinkään, mutta looginen päättely on tehokkaampaa, jos tieto voi kulkea kahteen suuntaan. Esimerkiksi kysymykseen ”kenelle pallo jäi?” saattaisi olla nopeinta vastata lukemalla tarina lopusta alkuun – ainakin jos se olisi pitempi tarina kokonaisesta koripallo pelistä. Eikö totta?
Lopulta pääsemme keskittymiskykyyn. Keskittymiskyky on meille ihmisille tärkeä, mutta millä tavoin me tai neuroverkot siitä hyödymme? Oleellista on että keskittymällä vähennetään tiedon kokonaismäärä, mutta kasvatetaan oleellisen tiedon osuutta merkittävästi. Eli kyse on jälleen tehokkuudesta.
Esimerkiksi näet valokuvan juhlista ja joku kysyy sinulta ”mitä tuolla tytöllä on kädessään?”. Todennäköisesti etsit vain tytöt ja katsot mitä heillä on kädessään. Helppoa eikö? Mutta olet jo käyttänyt keskittymiskykyä kaksi kertaa – ensin tyttöihin ja sitten käsiin. Ilman keskittymiskykyä joutuisit käymään kuvan jokaisen kohdan läpi, päättelemään mitä sillä kohdalla on ja muistamaan sen. Vasta kun olet käynyt läpi koko kuvan, voisit alkaa muistelemaan kaikista kuvassa näkyvistä asioista, missä kohdassa oli esine, joka oli käden välittömässä läheisyydessä, joka taas oli osa tyttöä. Kuulostaa aivan järjettömältä ja sitä se onkin. Siksi tarvitsemme keskittymiskykyä.
Neuroverkoissa keskittymiskyky mahdollistaa epäolennaisen tiedon käsittelemisen tehokkaasti jättämällä sen huomiotta tai pienentämällä sen vaikutusta, jolloin olennaisen tiedon käsittelyyn jää enemmän kapasiteettia.
Kuvaesimerkissä ihminen keskittyi ensin tyttöihin ja sitten heidän käsiinsä, myös neuroverkot voivat muodostaa hierarkisia keskittymiskykyjä. Esimerkiksi ensimmäisen tason keskittyminen voi tapahtua sanatasolla ja toisen tason keskittyminen lausetasolla. Alun ”kuinkas voitte tänään?” esimerkissä ”kissa” sanat saisivat hyvin pienen huomion, kun taas ”olo” sana saisi varmasti suuren. Lausetasolla kissaan liittyvät lauseet jätettäisiin vähälle huomiolle – paitsi jos kissan tekemiset vaikuttavat vastaajan oloon.
(Käytännössä keskittyminen tapahtuu siten, että tietyn neuronikerroksen vasteet syötetään yhdessä kysymyksen kontekstivektorin kanssa keskittymisneuroverkolle, joka tuottaa vasteille painokertoimet. Tärkeät asiat saavat suuren painokertoimen ja merkityksettömät asiat painottuvat nollaksi.)
Olemme nyt siis muuttaneet lauseet sanojen upotusvektoreiksi ja syöttäneet ne neuroverkolle, joka pystyy lähimuistinsa ansiosta tekemään loogisia päätelmiä lauseiden merkityksistä. Kaksisuuntaisuus ja keskittymiskyky tehostavat tiedon käsittelyä. Lopputuloksena neuroverkon vastekerroksen neuronit aktivoituvat lauseiden merkityksen mukaan, esimerkiksi, lause ”tosi hyvin menee” aktivoi ”vointi=hyvä” neuronin, kun taas alun esimerkki aktivoisi ”vointi=huono”, ”kipua=on” ja ”sydänoireita=on” neuronit.
Omasta mielestäni keskittymiskyvylliset pitkän lähimuistin neuroverkot ovat todella mielenkiintoisia ja omaavat valtavan potentiaalin. Niistä pystytään muodostamaan neuroverkkoja, jotka osaavat vastata kysymyksiin lukemansa/kuulemansa perusteella. Kuinka paljon mahdollisuuksia tällä onkaan? Siis puheeseen perustuvien käyttöliittymien lisäksi esimerkiksi erilaisten dokumenttien automaattisten analyysien ja tiivistelmien luomisessa, sekä niihin perustuvien ennusteiden luomisessa? Eikä tiedon tarvitse olla edes luonnollista kieltä, vaan data tai osa siitä voi olla vaikkapa jonkin sensorin tuottamaa dataa.
Keksitkö hyvän sovelluskohteen omasta taustastasi? Kerro meillekin.
Blogi sarjan seuraavassa osassa keskustelemme millaista koulutusaineistoa tarvitsemme, miten sitä saadaan ja rikastetaan. Sen jälkeen rakennamme koodiesimerkein yksinkertaisen pitkän työmuistin neuroverkon, joka ymmärtää selkeää suomea.