Me Onervalla kehitämme Onerva Bottia eli keskustelevaa tekoälyä vanhushoivaan. Edellisessä osassa tätä blogisarjaa käsiteltiin asiaa yleisemmällä tasolla ja nyt mennään sitten jo vähän tieteeseen ja koodaukseen eli avataan vähän konepeltiä. Blogisarjan seuraavissa osissa edetään hiljalleen syvemmälle ja välillä tulee teknisiä termejä, mutta yritän selittää niitä tarpeen mukaan.
Onerva Botin tekoälyssä on kolme osaa: 1) puheesta tekstiksi (speech-to-text, STT), 2) merkityksen tai aikeen tunnistus lauseista (intent discovery) ja 3) keskustelun kulun ohjaus (dialog flow control).
Tällä hetkellä käytämme Googlen Cloud Speechia ensimmäisessä vaiheessa muuntamaan puheen tekstiksi. Tämä tullaan korvaamaan myöhemmin omalla ratkaisullamme, kunhan saamme kerättyä tarpeeksi puhetta. Tähän meillä on jo hyvät suunnitelmat. Se tehdään yhteistyönä, joukkoistuksen avulla ja vapaan lähdekoodin periaatteiden mukaisesti, mutta tästä enemmän myöhemmin. Päälle vielä ripaus omaa dataa suoraan hoiva-asiakkailta ja voilà!
Keskitytään tällä kertaa merkityksen ymmärtämiseen tekstistä. Merkityksen ymmärtäminen tekstistä eli luonnollista kieltä ymmärtävän (engl. natural language understanding, NLU) tekoälyn kehittäminen on haastava tekoälyongelma.
Onneksi meidän ei yleensä tarvitse luoda tekoälyä, joka ymmärtää kieltä yhtä laajasti kuin ihminen.
Esimerkiksi Onerva Botin osalta jokainen käyttötapaus rajataan suppeaksi kokonaisuudeksi, jolloin tekoälyn tarvitsee ymmärtää keskustelun merkitys vain rajatussa aihepiirissä. Rajattu aihepiiri mahdollistaa hyvän suorituskyvyn nykyisillä NLU-menetelmillä. Käyttötapauksia lisätään ja laajennetaan asteittain, jolloin niitä vastaava ongelma-avaruus kasvaa hallitusti hyvin määriteltyinä osaongelmina.
Ensimmäinen vaihe lauseiden merkityksen ymmärtämisessä on muuntaa lause neuroverkolle sopivaan muotoon. Neuroverkot käyttävät vektoreita, matriiseja ja tensoreita laskennassa eli ne käsittelevät lukuja. Lauseet muutetaan luvuiksi pilkkomalla ne sanoiksi ja muuttamalla jokainen sana vektoriksi. Neuroverkolle lause siis näkyy sarjana sanavektoreita.
Hei, tässä Onerva Botti. Kuinka voitte tänään?
[100..00] [000..01] [001..00] … [010..00]
Mielenkiintoista on, että muutettaessa lauseet sanavektoreiksi tapahtuu melkoisesti sanojen ”luonteen ymmärtämistä”, jos käytetään hyväksi sanajen upotusta (word embedding).
Sanojen upotus on itsessään mielenkiintoinen koneoppimismenetelmä ja tutustutaan siihen seuraavaksi.
Yksinkertaisimmillaan sanoista saadaan vektoreita numeroimalla ne juoksevalla numeroinnilla eli sanat indeksoidaan. Kun sana esiintyy lauseessa, sitä vastaavassa sanavektorissa ovat kaikki muut elementit nollia, paitsi sanan indeksiä vastaava elementti, joka saa arvon yksi (one-hot vector). Esimerkiksi
kissa = [1,0,0,…, 0]
koira = [0,1,0,…, 0]
naukua = [0,0,1,…, 0]
Tällaisen informaatiotiheys on hyvin pieni eli se on harva ja informaatiosisältö on hyvin mitätön eli se ei kuvaa mitenkään sanojen ”luonnetta”. Siksi käytetään usein sanojen upotusta (word embedding), jossa indeksivektori muunnetaan upotusvektoriksi. Informaatiotiheys kasvaa, sillä upotusvektorin dimensio (elementtien määrä) on huomattavasti pienempi (~100) kuin indeksivektorin (~100 000).
Lisäksi upotusvektori sisältää tietoa sanan luonteesta. Esimerkiksi sana ”kissa” ja ”koira” ovat kielellisesti lähempänä toisiaan kuin ”kissa” ja ”kivi” tai ”aamu”, joten tavoitteena olisi, että ”kissan” ja ”koiran” upotusvektorit olisivat lähempänä toisiaan kuin ”kissan” ja ”kiven” tai ”aamun”. Esimerkiksi kuvitteellisessa kaksiulotteisen upotusvektorin tapauksessa voisi olla
kissa = [9, 8]
koira = [8, 9]
kivi = [5, 3]
aamu = [2, 4]
Kuinka voimme opettaa tekoälylle sanojen luonteita?
Perusajatuksena on että lauseessa lähekkäiset sanat liittyvät jollain tavalla toisiinsa, esimerkiksi ”kissa naukuu” ja ”koira haukkuu”.
Kissa ja naukuminen liityvät toisiinsa ja kissa liittyy todennäköisemmin naukumiseen kuin haukkumiseen. Toisaalta samanlaisten sanojen kanssa esiintyvät sanat ovat samankaltaisia, esimerkiksi ”minulla on kissa lemmikkinä” ja ”minulla on koira lemmikkinä”, eli sekä kissa että koira ovat lemmikkejä.
Sanojen upotukseen tarkoitetussa Skip-Gram -menetelmässä lauseesta valitaan keskussana ja sitä ympäröivät sanat tiettyyn rajaan asti. Neuroverkkoa koulutetaan siten, että keskussana on syöte ja ympäröivät sanat ovat vaste. Esimerkiksi jos lause on ”kissa naukuu navetan katolla”, keskussana on ”kissa” ja ikkunan koko on kaksi, syöte – vaste -sanaparit ovat
kissa => naukuu
kissa => navetan
jos keskussana on ”naukuu”, sanaparit ovat
naukuu => kissa
naukuu => navetan
naukuu => katolla
Kun neuroverkolle syötetään paljon tekstiä koulutusvaiheessa, alkaa sanojen välille muodostua kytkentöjä. Koska kissa voi naukua monessa eri paikassa, ”kissa” ja ”naukuu” tulevat kytkeytymään voimakkaammin kuin ”naukuu” ja ”navetta” ja neuroverkko oppii sanojen luonteita.
Kun koulutuksen jälkeen neuroverkolle syötetään sana ”kissa”, aktivoituu kissan upotusvektori, joka kuvaa sitä minkälaisten sanojen ympäröimänä eli minkälaisessa kontekstissa sana ”kissa” yleensä esiintyy.
(Itseasiassa Skip-Gram -upotusvektorit saadaan autoencoder-tyylisen neuroverkon pullonkaulana toimivasta lineaarisesta piiloneuronikerrosta. Lisää Skip-Gram -menetelmästä täällä.)
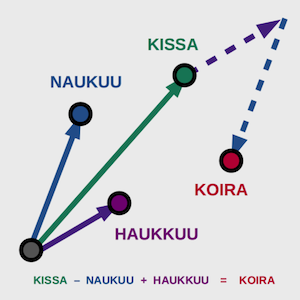
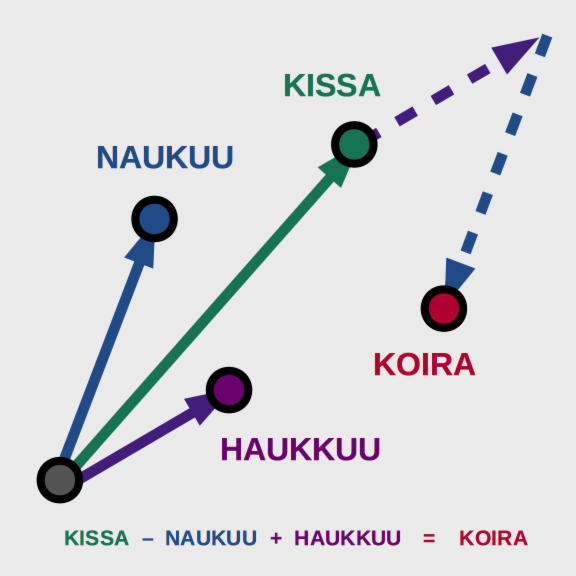
Upotusvektoreilla on myös mielenkiintoisia ominaisuuksia, jotka kuvaavat hyvin sitä, kuinka ne sisältävät tietoa sanojen luonteesta. Esimerkiksi niillä voidaan vastata kysymykseen ”jos kissa naukuu, niin mikä haukkuu?” laskemalla vektoreilla seuraavasti
”kissa” - ”naukuu” + ”haukkuu” = ”koira”
tai ”jos kuningas on mies, niin mikä on vastaava nainen”
”kuningas” - ”mies” + ”nainen” = ”kuningatar”.
Eli jo sanojen upostusvaiheessa tapahtuu merkkittävää ymmärtämistä ”sanojen luonteesta”, vaikkei se vielä lauseiden merkityksen tulkintaa riitäkkään.
Mutta miksi emme voisi oppia upotuksia lennosta samalla, kun koulutamme neuroverkkoa ymmärtämään lauseiden merkityksiä?
Hieno ominaisuus Skip-Grammin kaltaisille menetelmille on, että ne voidaan kouluttaa ohjaamattomalla oppimisella (unsupervised learning), kuten yllä on kuvattu. Eli ihminen vain antaa teksti koneelle ja kone oppii itsenäisesti upotukset. Tällöin voidaan käyttää valtavia datamassoja verrattuna ohjattuun oppimiseen, jota lauseiden merkitysten ymmärtäminen on. Ohjaamattomalla oppimisella saadaan siis helposti kattavia upotuksia.
Upotukset ovat yleensä uudelleenkäytettäviä. Facebook AI Research yksikön kehittämälle fastText -upotusmenetelmälle on saatavissa esikoulutettuja upotuksia, jotka on koulutettu julkisesti saatavilla olevilla massiivisilla tekstiaineistoilla, kuten Wikipedia ja Common Crawl. Tällöin upotusten laatu tai ainakin ”kattavuus” on hyvä ja ne ovat erinomaisia tapoja päästä nopeasti alkuun. Jos haluat kokeilla itse upotuksia ja niiden ominaisuuksia, niin tutustu fastTextiin ja sen valmiisiin upotuksiin, jotka löytyvät myös suomeksi.
Sivuhuomautuksena mainittakoon että Skip-Grammin kaltaisia menetelmiä voidaan käyttää myös esimerkiksi verkkokauppojen suositusten luomiseen, mutta myös moneen muuhun asiaan löytämään ”muita samanlaisia tai tähän liittyviä asioita”. Ja tämä voidaan tehdä ohjaamattomasti eli ihmisen ei tarvitse luokitella koulutettavia asioita.
Upotusten jälkeen voimme siirtyä koostamaan upotusvektoreista lauseita ja niiden merkityksiä ohjatulla oppimisella. Tästä enemmän seuraavassa osassa.
Lue myös tämän blogisarjan muut osat: Osa 1, Osa 2