Onerva is building voice-operated virtual assistant for aging homecare customers.
Onerva-bot is conversational-AI in smart speaker (or in an app) that can have conversations with customer:
- Ask how she’s doing
- Ask if she will need the nurse to visit
- Orientate for the day
- Send messages to family members
- Send alarms to nurses
- Entertain by playing audiobooks, read the news and weather
- And allow customers with limited vision, to access digital services via voice (like buying groceries, see video in Finnish)
In this post we will go through Onerva’s technology and architecture.
So all you gear heads interested in Voice + AI + robotics, scroll down.

Why we need separate conversational-AI solution for healthcare?
Before we dig into our tech stack, let’s answer one of the most common question:
Why don’t we just use Alexa or Google Assistant?
There are few simple reasons:
- there is no general AI that can understand everything
- data security
- ability to modify everything
1. There is no general AI. Siri, Google, Alexa can’t understand eldercare context. Try telling Alexa or Siri, that you are feeling a bit of a pain in your stomach and see what happens. Try telling Google Assistant that you fell in the floor, can’t get up and need some help.
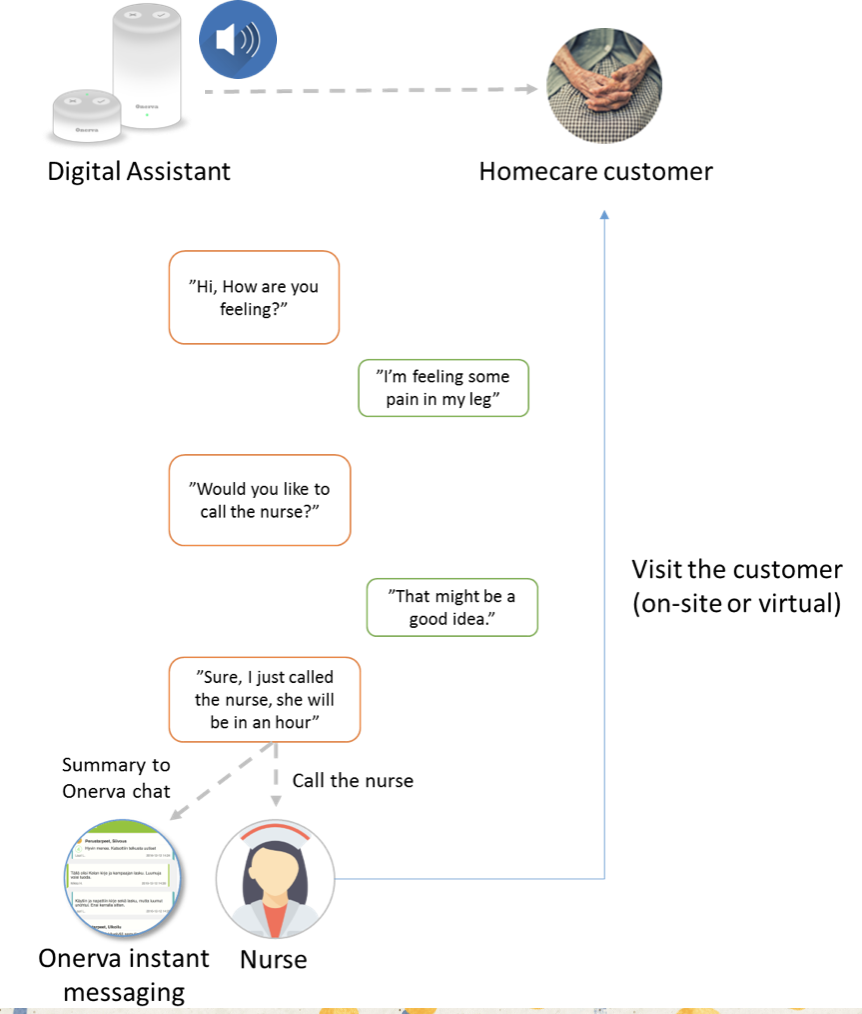 Each use case, each context must be taught to the algorithm/bot/AI. We need to collect and enter vast amounts of data in order the bot to understand context and nuances of aging customers.
Each use case, each context must be taught to the algorithm/bot/AI. We need to collect and enter vast amounts of data in order the bot to understand context and nuances of aging customers.
We can of course teach Siri and Alexa to understand also eldercare related speech but then comes other challenges as follows.
2. With Onerva-bot we are handling sensitive, personal data. All the components have to be GDPR (Europe) and HIPAA (US) compliant.
We cannot send the data into Amazon or Google servers. Or even if Google servers would stay inside EU and thus they would be GDPR compliant, our customer (care providers) might still want to keep the data on-premise. Or even inside the device/smart speaker i.e. it will never leave the end customers home.
3. We also need to have 100% control and ability to modify the language models, intent discovery model, dialog flows and how the smart speaker operates. We want to be able stick our fingers into the heart of the AI or the circuit boards and do some hard core scientific surgery.
Although we are creating product for homecare customers, the buying customer is healthcare provider (municipality, private operator). These operators have to have their own admin interfaces and there will be integrations from our smart speaker / conversational-AI into their systems. This will be done a lot easier with our own proprietary technology.
So because of these reasons we need our own conversational-AI + smart speaker.
But now to the tech.
Components and technology needed for voice operated conversational AI
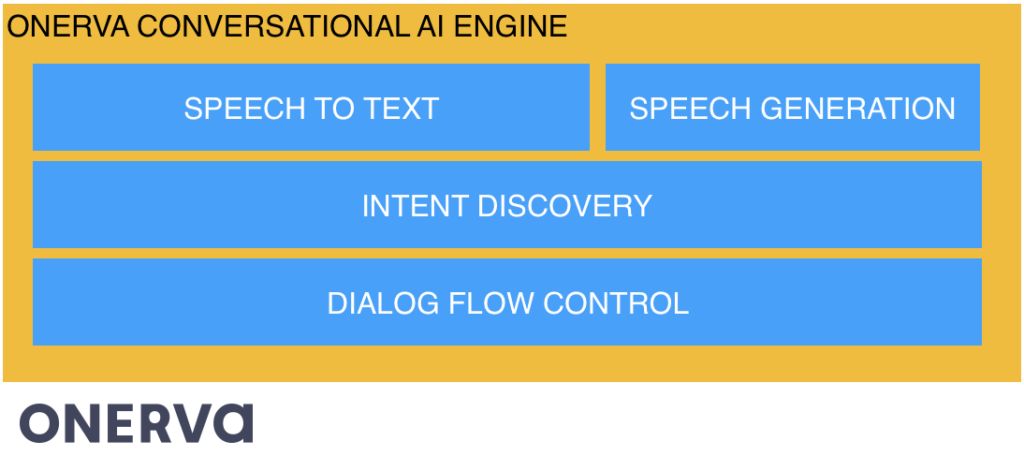
What are the components of Onerva’s conversational AI? We use the following modules in conversational AI engine.
- Speech-to-text module (audio in, text out)
- Intent discovery (text in, intents out)
- Dialog flow, conversation logic (intents in, command out)
- Speech generation (commands in, audio out)
Speech-to-text is trivial. Well not trivial but straightforward. It converts audio (voice-data) into text. Training a speech-to-text system requires huge amounts of voice-data, but the algorithms are well-known. A domain specific language model helps the system to choose the right word when two words sound similar. In our case, we must tune the language model to match how elders speak.
Intent discovery is the core. It is our most valuable asset. That includes the actual intelligence, the understanding what person says. Intent discovery picks intents/meaning from speech.
Consider the differences in following sentences:
”I’m thirsty” vs. ”I’m thirsty for your love”
”I’m dying to see you” vs. ”I’m dying, could you help?”
This intelligence we create by recording hundreds of hours of aging homecare customers speech in actual home care context. It’s all about the data. And we start to collect it now in 5 cities in Finland + doing nation wide crowdsourcing project among general population.
Because of the vast amount of voice data from aging customers, we can build the best model in this niche.
Dialog flow and conversation control is where we control how the conversations are leading us. This is where we have also the ”memory” of the conversation.
If customer mentioned pain in his leg earlier, we can ask about that.
This is also very context related and we use a lot of eldercare experts to create right kind of conversations flows. Customers with dementia sometimes tend to wonder around in their speech.
Speech generation is the part where we answer back to the customer. Currently we play pre-recorded audio recordings. So we don’t generate audio from text. Now we want to keep it simple and have limited number of answers and this can be done easily with prerecorded audio. Soon we will add text-to-speech capability.
Because we have 100% control in each part, we can add for example domain language models or local dialects in speech-to-text module. We can create our own dialog flows, add integrations into patient care systems, etc.
And we can even try to understand emotions and feelings based on voice. Which is actually one task in our roadmap.
Human-machine loop = quality assurance and faster learning curve
Important part of our tech stack is so called ”Bot-commander interface”.
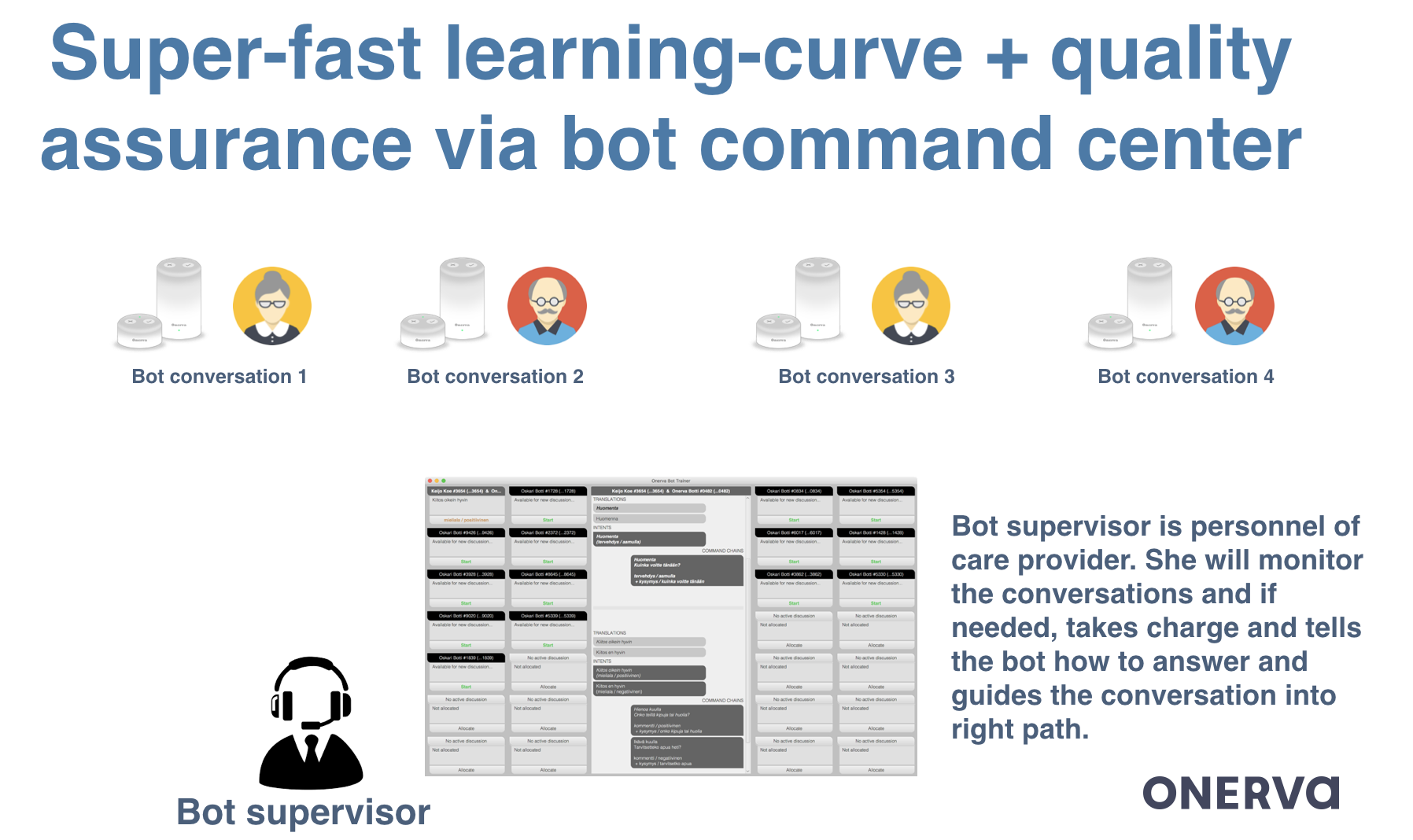
This is web application for Onerva-bot supervisor. She can monitor each bot conversation (even 100 at the same time). She will see an alarm if the bot doesn’t understand some sentence from customer and she can take control of that conversation.
With our point-and-click admin-interface, bot commander can choose the intent, i.e., tell the bot what the elder meant. And then the bot will again carry on the conversation.
This will ensure quality of the conversation and make it possible to go production from day one.
Initially, the bot commander will have more responsibility but as the bot learns more and more, she will let the bot work more independently. With each click, the bot learns on-the-fly while in production.
Smart speaker is just a one option to deliver virtual assistant
Ok, now we have our conversational-AI ready but we still need to get into the hands of homecare customer.
A smartspeaker is just one option. Because the intelligence is in our conversational-AI engine, we can deliver this capability via Onerva-API basically for any device.
So whether it’s a 3rd party smartspeaker, social robot, 3D printed old school telephone, Android/IOS application… you can use Onerva’s voice-operated virtual assistant in it. As long it has a mic, speaker, CPU and network card in it.
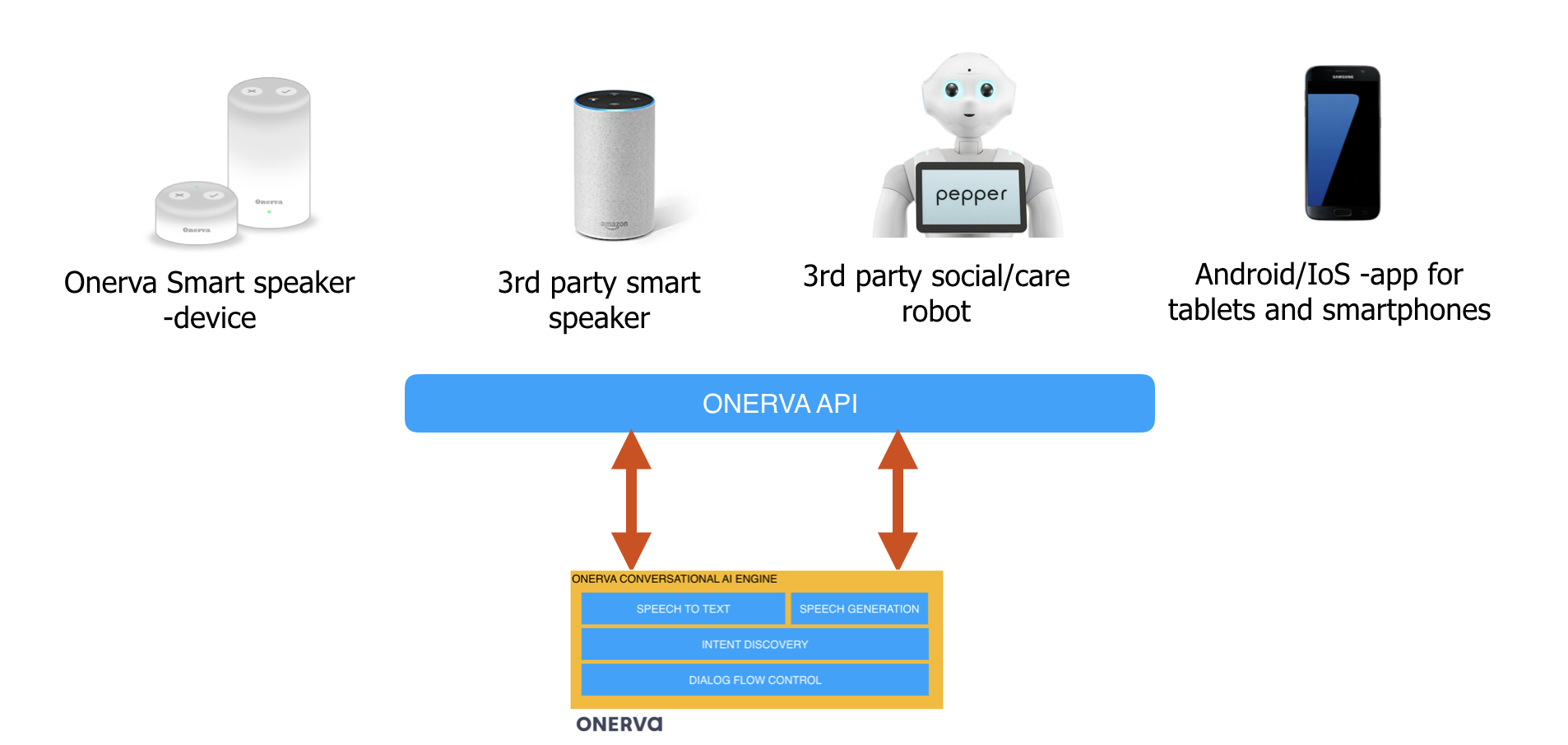
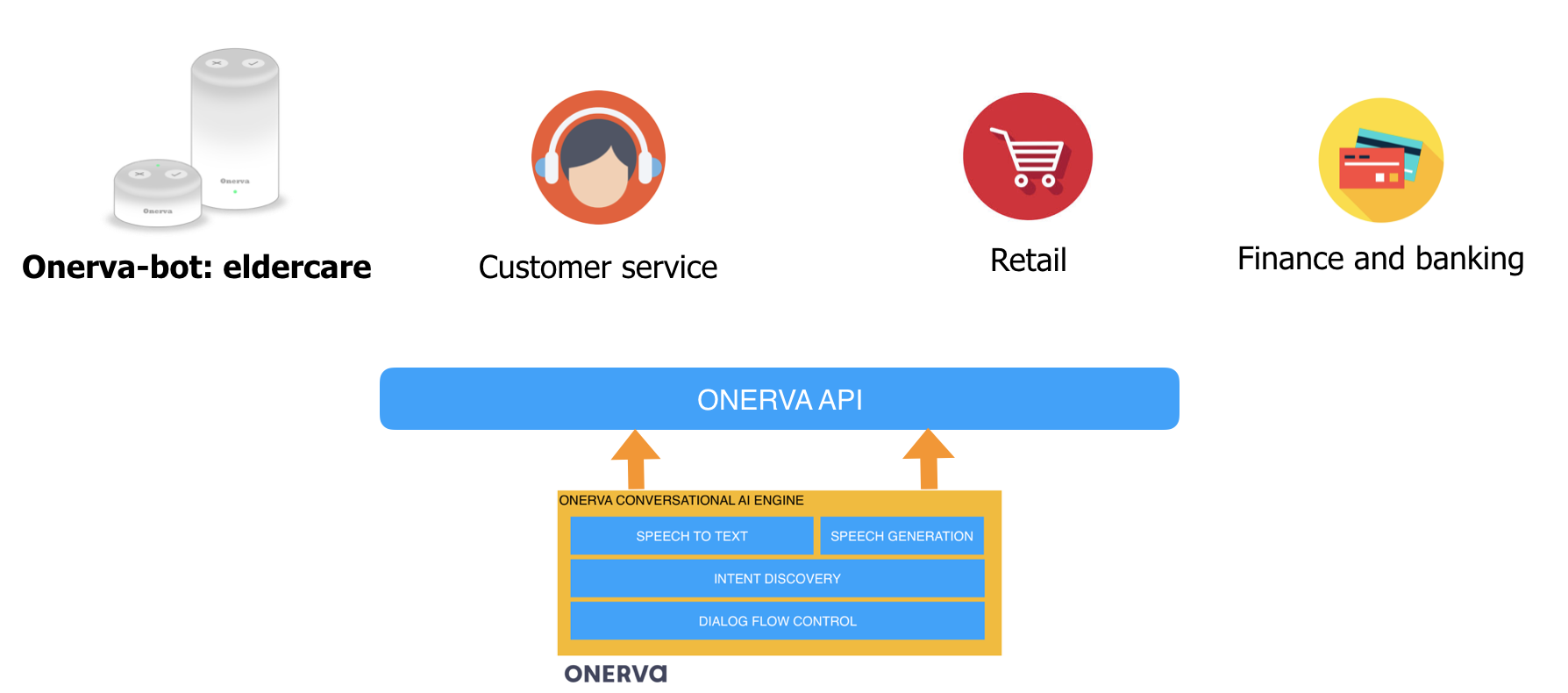
Using Onerva’s conversational AI engine in different industries
We focus in eldercare and we are making worlds best conversational-AI / virtual assistant for aging customers.
But Onerva’s conversational-AI engine with Bot-commander tool is not tied to just one domain. It can be used in other industries also. Whether it’s customer service, retail, transportation, manufacturing or finance and banking. Just to name a few.
If interested in testing it in your context or with your language, please let us know. It will take few weeks to set up a prototype.
That’s all for now.
When we progress more and get more data (especially via crowdsourcing), we will post more detailed info how we are using deep learning (neural networks) models for example in intent discovery. But that’s a post that I will leave to my colleague Lauri, our CTO.
Btw… we are opening a seed round Q2/2020. If interested in joining us (or you know investors interested in voice+AI and/or healthcare) don’t hesitate to contact me: Ville at onervahoiva.fi, p. +358 50 326 4989, LinkedIn